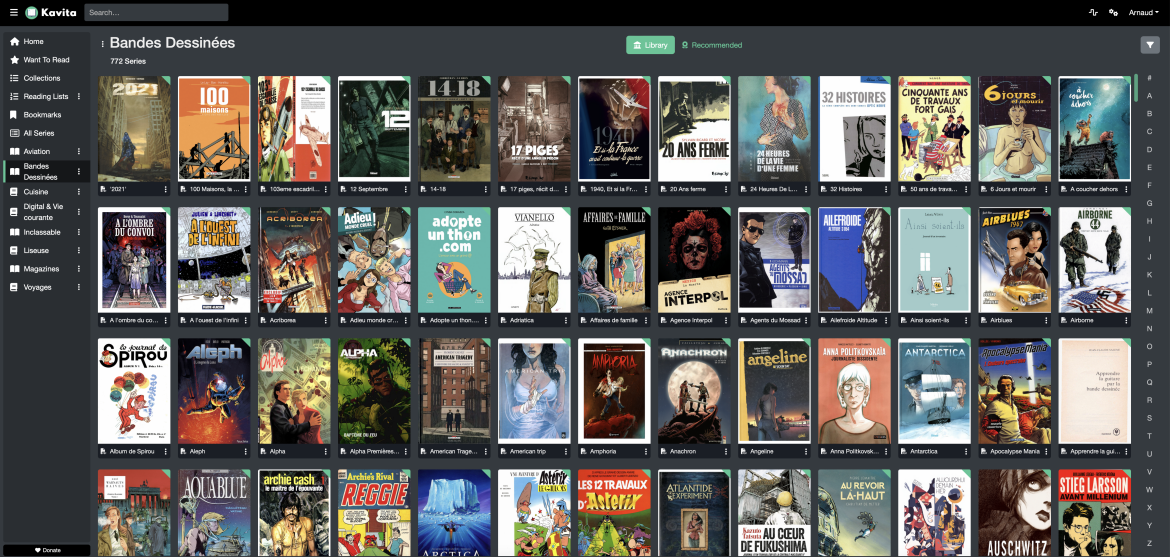
J’ai trouvé Kavita par hasard en parcourant Reddit. Kavita se présente comme le Plex des ebooks. Il est vrai que la philosophie et l’interface ressemblent à Plex.
Kavita accepte les cbz, les cbr, les epub et les pdf.
C’est très facile à installer (conteneur Docker) et un peu plus compliqué de s’y retrouver une fois les médias « indexés »: En effet, selon le type de document (cbz, epub et pdf), la boucle d’indexation est différente. Toute l’indexation passe par le nom du fichier sauf pour quand certaines metadata sont présentes dans le fichier. Ca peut faire un beau désordre dans l’affichage… J’ai dû renommer en masse pas mal de mes livres mais je suis content du résultat 🙂
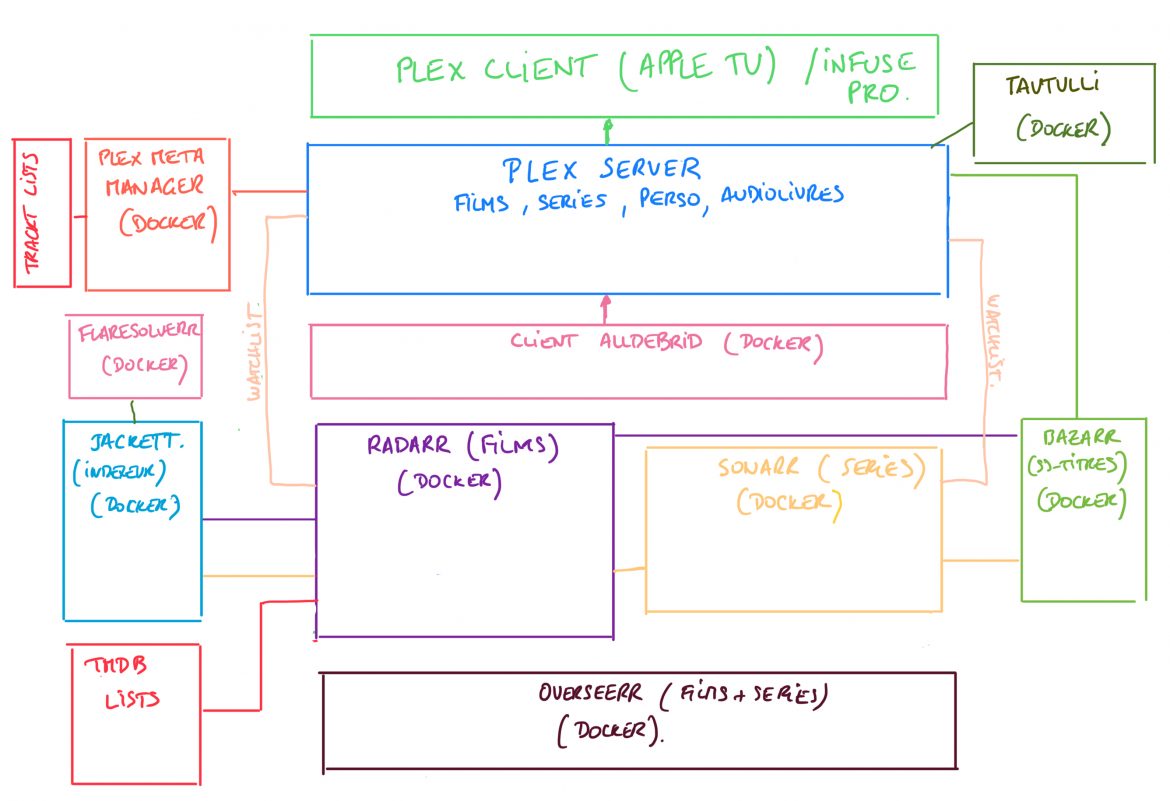
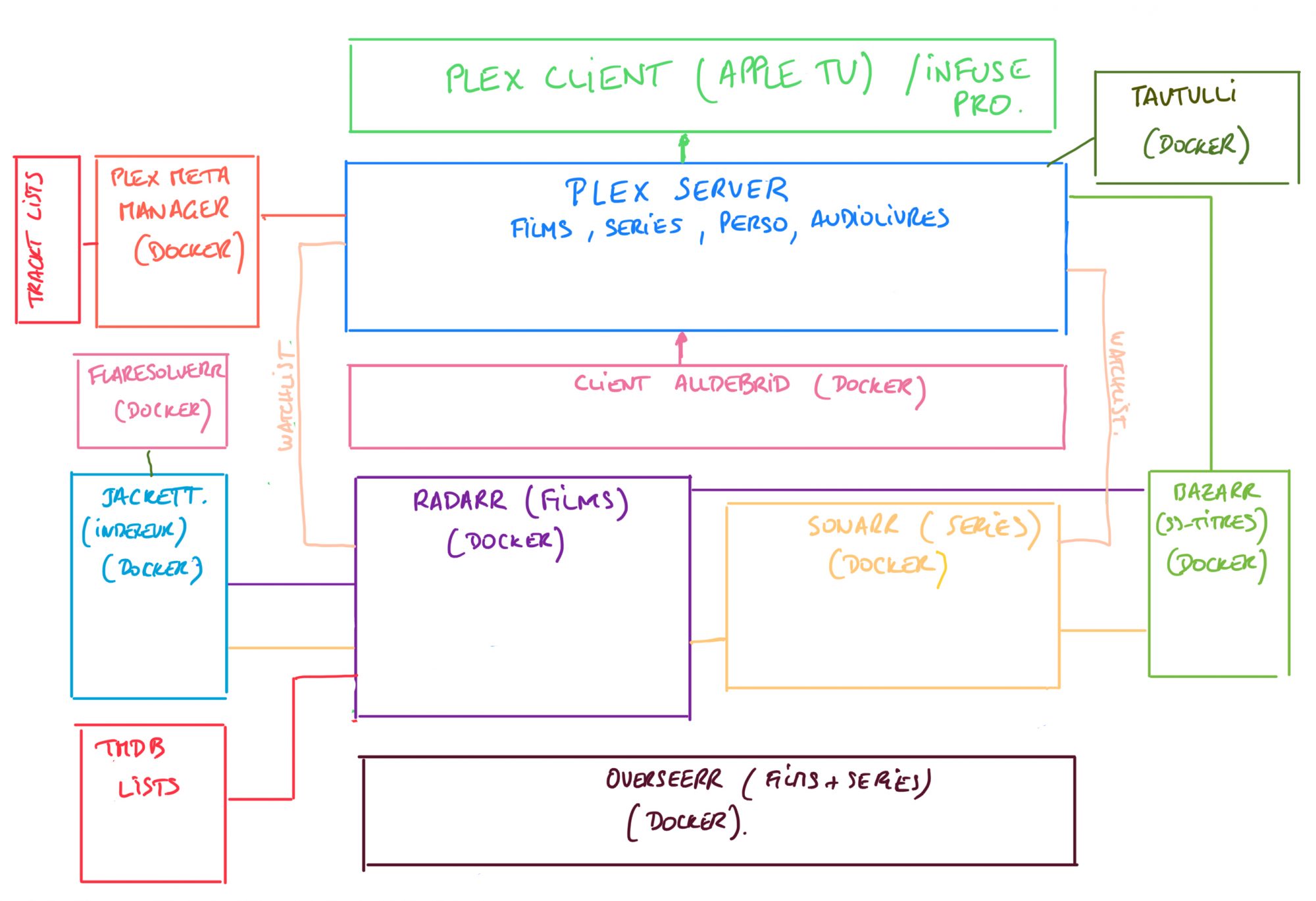
Un petit article rapide (et surtout un dessin) pour vous montrer comment j’ai totalement automatisé mon processus d’ajout de films et séries (pour moi et pour mes utilisateurs).
Le schéma se lit de bas en haut. Quelques explications à la suite…
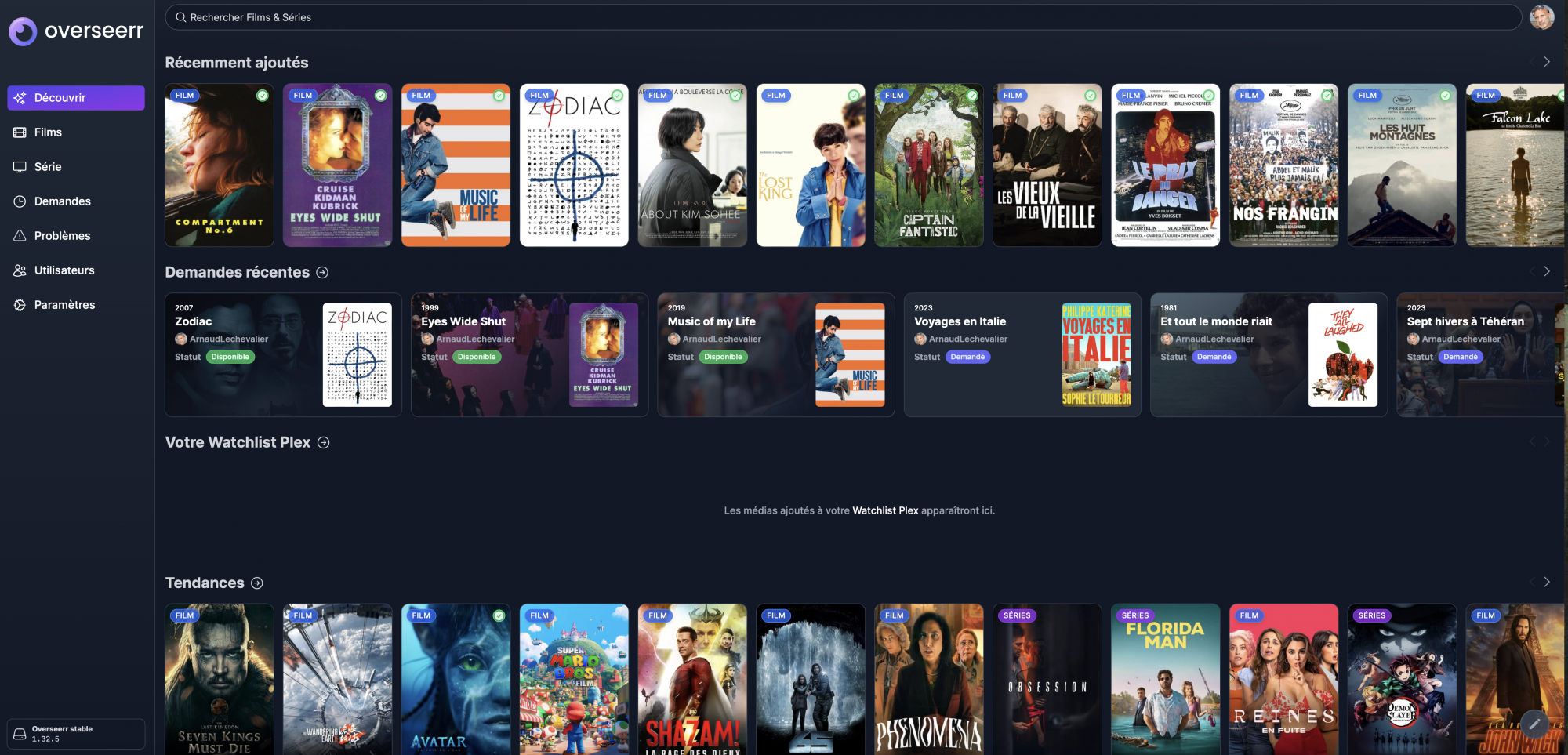
Tout commence par Overseerr qui est le portail de demandes pour les films et les séries. Overseer peut récupérer automatiquement les users Plex et la connexion se fait avec le compte Plex de l’utilisateur, rien de plus simple.
On fait son marché ici. On peut préciser des tags (MULTI pour du multilangues), l’interface est très propre. Ca marche avec Docker. Overseer va orienter les requêtes vers Radarr ou Sonarr selon le type de demande (Film ou Série).
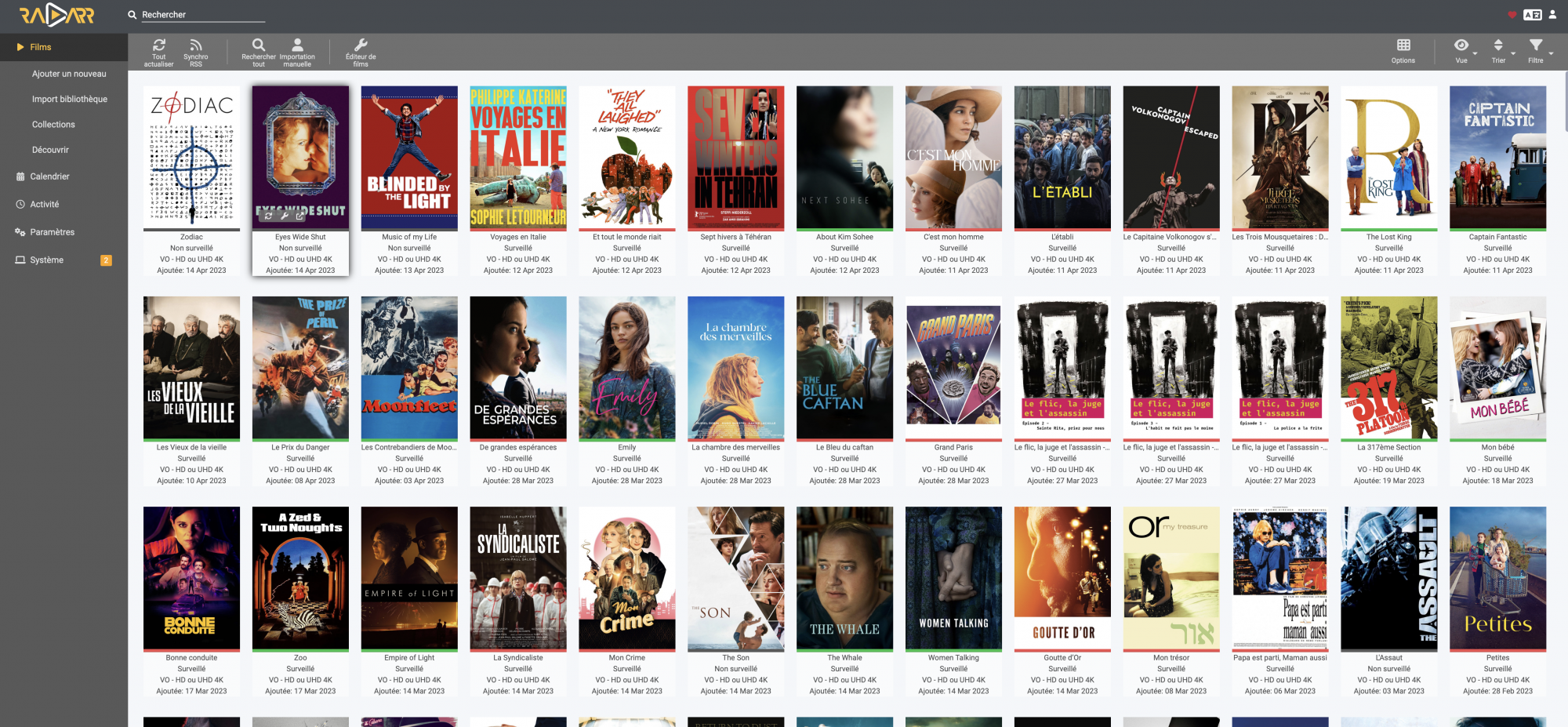
Radarr permet de récupérer les films demandés arrivant directement de Overseerr. Il est possible de demander aussi directement des films dans Radarr.
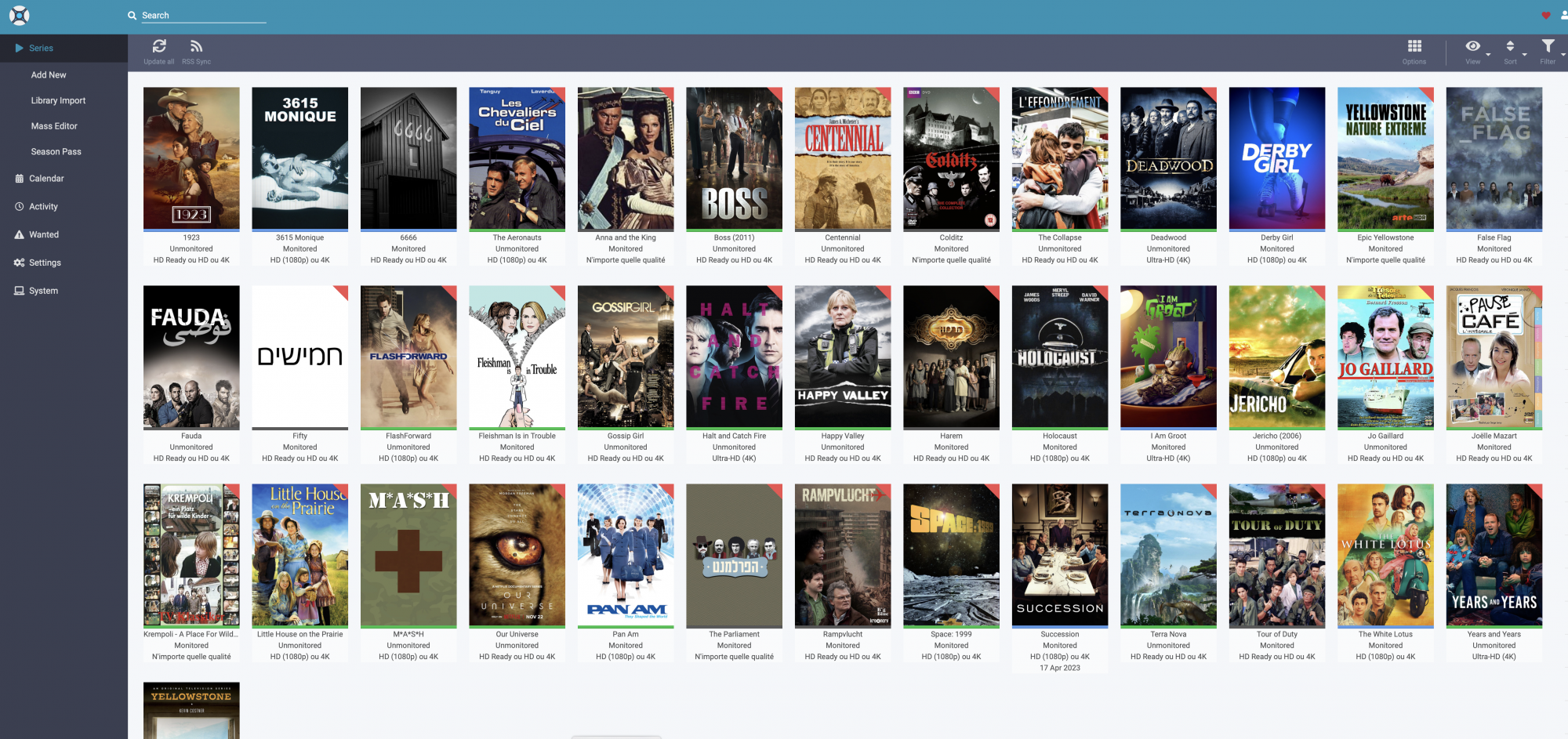
Sonarr quand à lui permet de récupérer les séries, les deux applications sont quasiment des clones.
Radarr et Sonar (qui fonctionnent très bien avec Docker) vont rechercher les torrents sur tout un tas de sites de torrents qui sont gérés par l’indexeur de sites de torrents Jackett (Docker). La magie de tout cela est que Radarr et Sonarr scrutent périodiquement (plusieurs fois par heure) toutes les nouvelles publications de torrents pour enclencher un téléchargement dès l’apparition d’un torrent correspondant à une recherche. De plus, si un nouveau torrent propose une version plus conforme à vos paramètres de recherche (spécifiques ou par défaut), par exemple du MULTI, du 4K ou un encodage plus performant, il va remplacer le média existant par le nouveau média.
Les sites que j’utilise configurés dans Jackett:
La mise à jour des url des sites est automatique. Il faut paramétrer les sections qui vous intéressent pour chaque site (des choix prédéfinis sont proposés).
Certains sites sont protégés par Cloudflare (par exemple yggtorrent). Il est nécessaire d’avoir un module permettant de challenger Cloudflare, pour cela j’ai ajouté FlareSolverr (Docker) qui permet de résoudre les challenges (gros conteneur Docker).
J’ai également ajouté le module Bazarr (Docker) qui récupère automatiquement les sous-titres sur différents sites (en effet, je regarde systématiquement en VO, films comme séries).
A signaler, je tiens à jour une liste sur TMDB des films passés en revue au « Masque et la plume« , les films de cette liste (publique) sont automatiquement importés lors de l’ajout de films dans la liste.
Maintenant que Radarr et Sonarr ont toutes les informations pour télécharger les torrents, il leur faut un client de téléchargement, j’utilise pour cela un client sous Docker qui permet de passer sous les radars de HADOPI, rdt-client, un client AllDebrid qui fonctionne sous Docker que je recommande et que je décris ici (lien de parrainage).
Le média téléchargé, Radarr et Sonarr se débrouillent très bien pour le placer au bon endroit pour que votre serveur Plex le détecte et l’ajoute automatiquement à sa bibliothèque. A signaler que Overseerr prévient par mail le demandeur que sa requête est exécutée.
Il reste à regarder le tout, pour cela, j’utilise une Apple TV avec le client Plex (et parfois Infuse Pro, ça dépend).
On peut rajouter 2 modules intéressants (mais pas indispensables) au dispositif:
Tautulli (Docker).
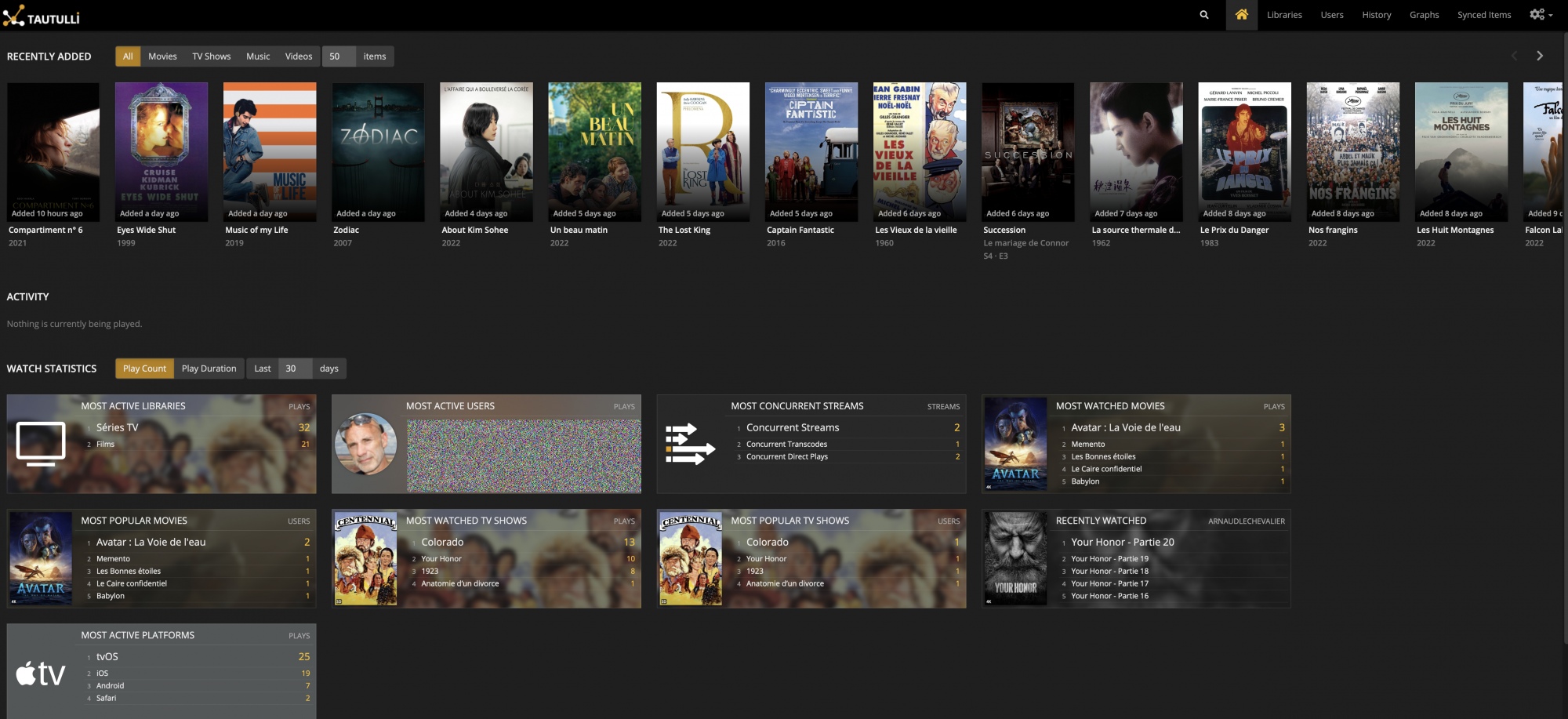
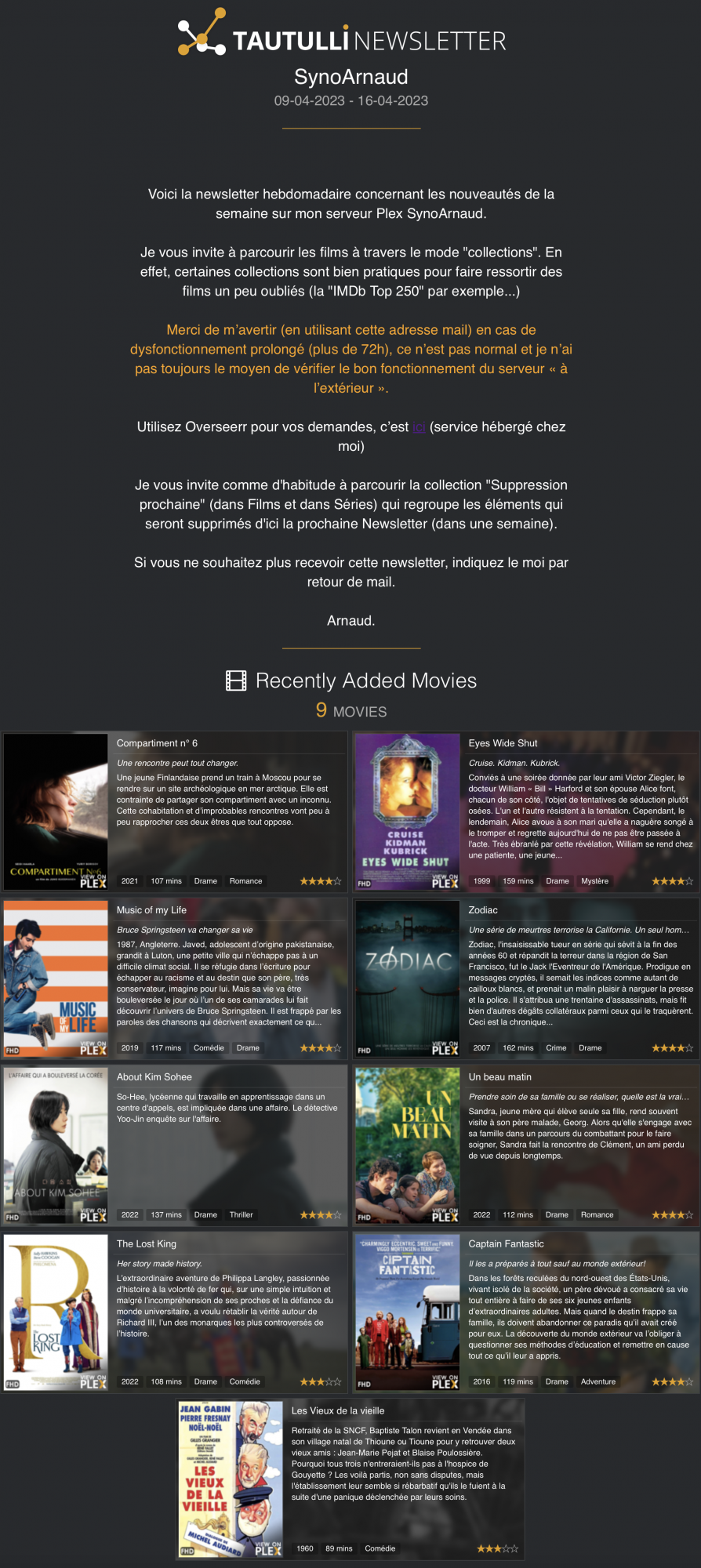
Tautulli permet de contrôler ce qu’il se passe sur le serveur à tout instant: Qui lit quoi, à partir de quoi et d’avoir des statistiques sur l’utilisation en général. Mais ce n’est pas le plus intéressant: Je l’utilise surtout pour générer une Newsletter hebdomadaire pour mes utilisateurs avec toutes les nouveautés de la semaine. La newsletter est automatiquement générée et envoyée.
Exemple de Newsletter générée par Tautulli:
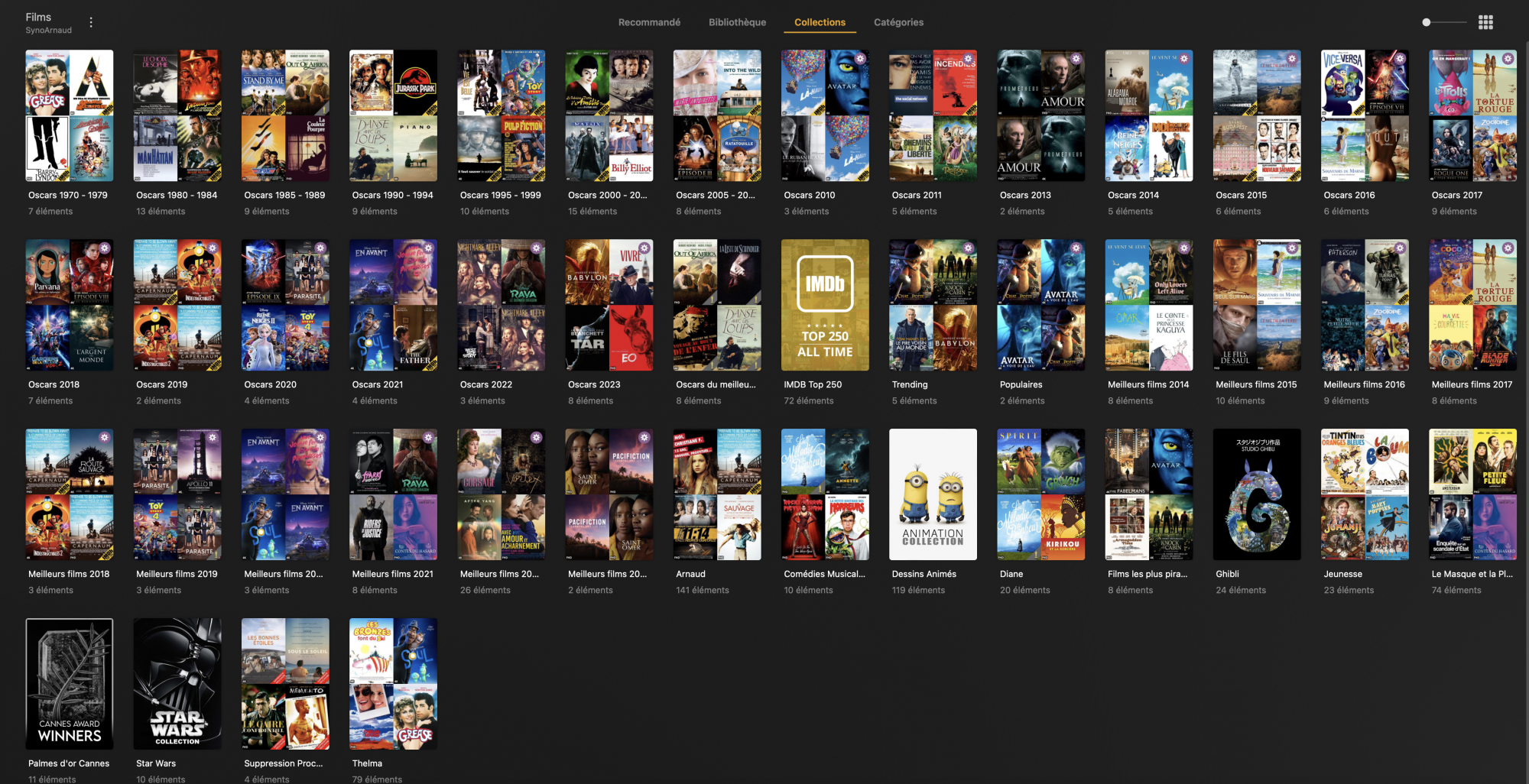
Et pour terminer, le module qui est certainement le module le plus complexe à paramétrer: Plex Meta Manager (Docker).
Plex Meta Manager permet (entre autres choses) de créer des collections de médias en fonction de listes existantes sur différents site de critiques de films/séries. Ce module permet aussi de paramétrer la modification des affiches de films pour indiquer des éléments supplémentaires. Par exemple la définition media (FHD, 4K, SD) ou une information indiquant que vous allez supprimer prochainement le média en question (car oui, tout ça prend de la place !).
Voici un exemple d’affichage des collections de films qui m’intéressent. Ces collections sont gérées automatiquement. Vous pouvez créer aussi vos propres règles et avoir vos propres collections automatiques. Ainsi, on peut voir sur cette copie d’écran la collection « Le Masque et la Plume » qui provient directement de la liste que je tiens à jour sur TMDB. Un simple ajout sur TMDB dans cette liste met à jour (ou mettra à jour) la collection Plex dès que le films sera dispo quelque part…
Quelques exemples de personnalisation automatique d’affiches de film (tout est paramètrable).
Voilà, j’espère que cet article vous aura inspiré ! Si vous avez d’autres modules chouettes à ajouter, n’hésitez pas à me laisser un commentaire !
J’ai découvert il y a peu Ombi, logiciel gratuit (donation) qui fonctionne avec Plex. Ombi permet de constituer une base de souhaits pour votre contenu Plex. Ainsi, si comme moi vous partagez votre Plex avec des amis ou de la famille, si un contenu n’est pas disponible sur votre Plex, il est possible de le demander par l’intermédiaire d’Ombi.
Présentation
Chez moi, Ombi tourne sur le Synology dans un conteneur Docker. L’image Docker porte le nom de linuxserver-ombi. Pour installer une image dans Docker sur Synology, je vous invite à consulter cet article. Ombi va se connecter à votre serveur Plex et offrir une belle interface à vos utilisateurs.
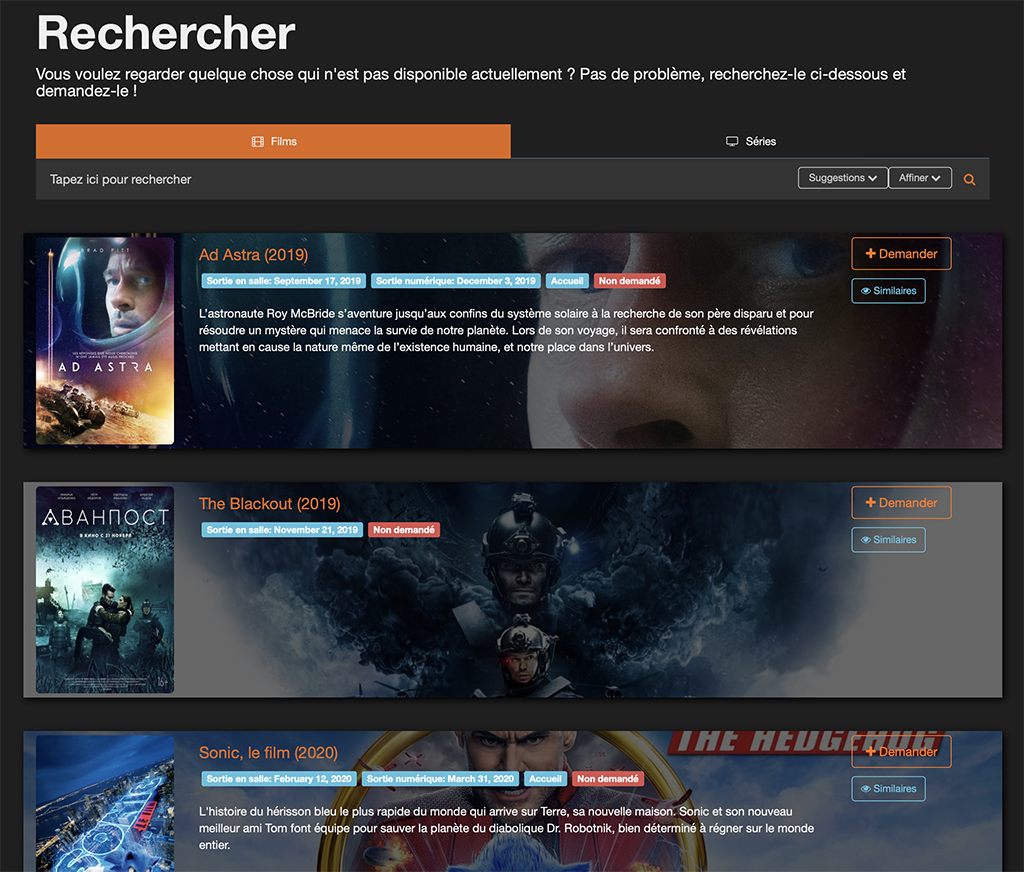
Interface de recherche de Ombi
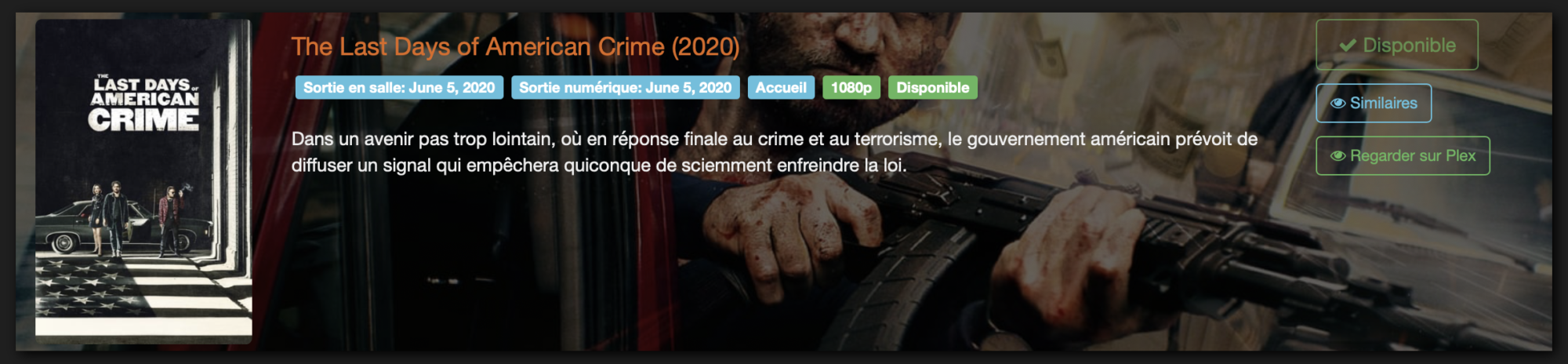
Cette interface permet à l’utilisateur de rechercher un contenu, film ou série. Vous devez lui avoir créé un compte et avoir ouvert le bon port de communication sur votre box/routeur. Il est cependant possible de se connecter avec son compte Plex (si Plex OAuth est activé). Cette recherche va s’effectuer de manière transparente sur le site The movie database (base de données de films et séries). Par défaut, l’interface propose des films et séries populaires sur Ombi (les titres les plus recherchés).
On peut voir sur la copie d’écran précédente que Ad Astra est proposé. Sa date de sortie en numérique est indiquée (important !). On voit aussi la balise « Non demandé » qui indique que le fichier n’a pas été demandé par le biais d’Ombi sur ce serveur Plex. Il est possible pour l’utilisateur de « Demander » le fichier à l’administrateur du Plex.
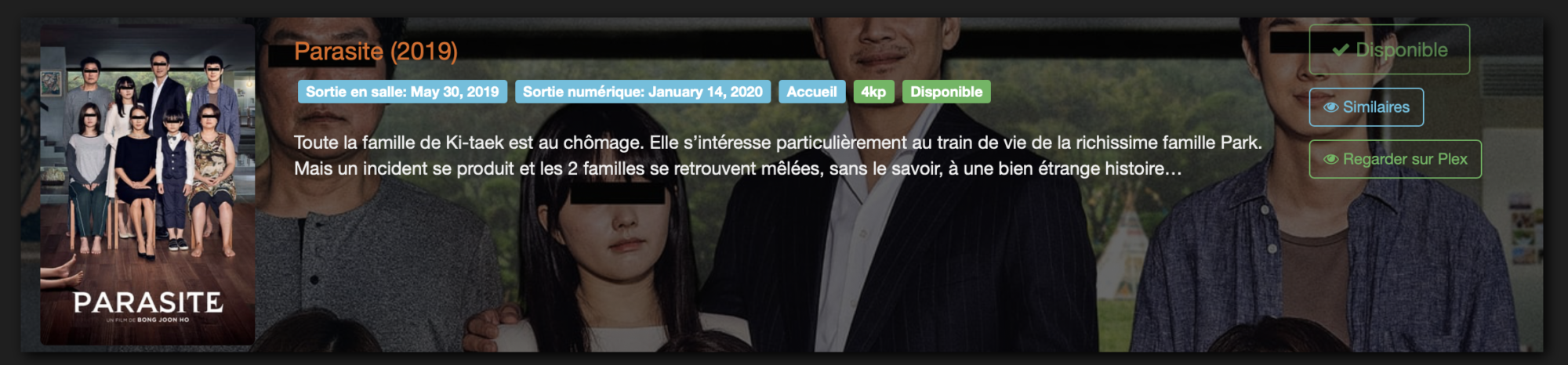
Dans le cas où un fichier est déjà présent, Ombi l’indique de cette manière:
Ombi est déjà présent sur le serveur et ne peut être demandé ! (statut Disponible)
A signaler qu’Ombi ne va s’assurer de la présence ou non du contenu que sur le serveur Plex sur lequel il est connecté. Ainsi, si vous avez accès à d’autres serveurs amis à partir de votre Plex, Ombi ne trouvera pas ces contenus….
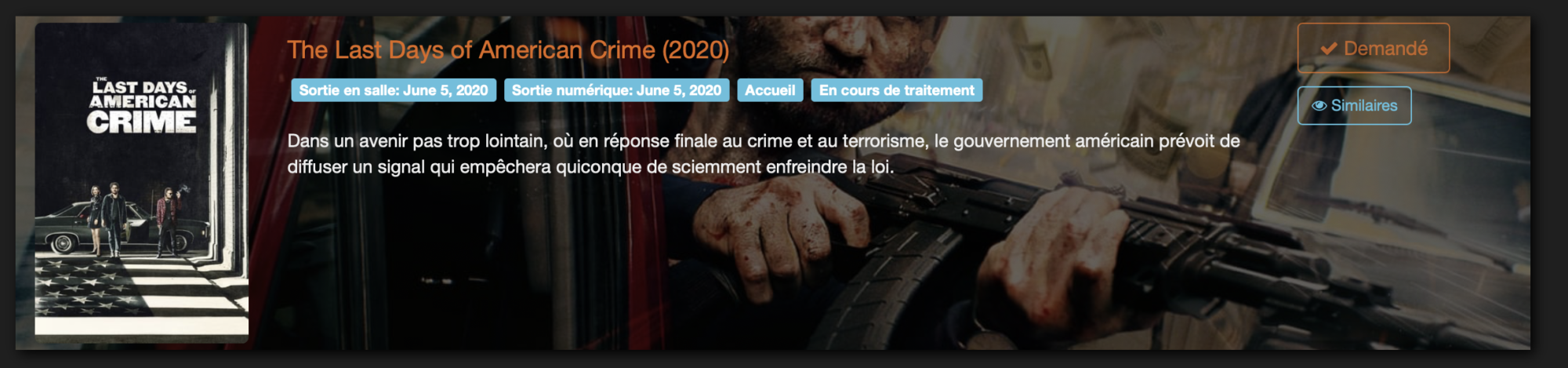
La demande de contenu par un utilisateur
Lorsqu’un utilisateur clique sur le bouton « Demander » d’un contenu qu’il a recherché sur Ombi, le statut du contenu passe à « Demandé ». Ainsi, un autre utilisateur sait qu’une demande de mise en ligne de ce contenu est en cours et qu’il n’est plus utile de le demander s’il comptait le faire..
Ombi – Contenu demandé
Un mail est envoyé automatiquement à l’administrateur du serveur Plex pour lui indiquer les références du film (ou de la série) demandée (et qui la demande). L’administrateur peut valider ou non la demande (en général, il la valide …). Il ne lui reste plus qu’à se mettre en chasse du fichier numérique correspondant. Une fois celui-ci mis en ligne sur le serveur Plex, Ombi le détecte tout seul et le statut de la demande est modifié.
Ombi, le contenu est disponible !
L’utilisateur demandeur est prévenu par mail que sa demande est exaucée et que le contenu peut maintenant être visionné sur le serveur Plex.
Petite cerise sur le gateau: Vous pouvez définir une petite newsletter (facultatif) qui indique aux utilisateurs de votre choix les différentes nouveautés de la semaine disponibles sur votre serveur Plex. Ceux-ci recevront un petit mail bien léché listant le nouveau contenu dans la limite de leurs accès sur les bibliothèques de votre serveur !
Il est possible d’interfacer Ombi avec Sonarr (pour le téléchargement automatique des séries) et avec CouchPotato (pour les films). Ainsi, les « administrateurs » paresseux n’ont même plus besoin de lever le petit doigt pour alimenter leur Plex !
Conclusion
Un petit soft pas gourmand très pratique. Plutôt que de recevoir un mail de vos utilisateurs (amis, famille) avec parfois des titres inexacts ou bien des films avec plusieurs remake et le même titre. Là, plus d’ambiguïté ! Vous avez le titre et l’année, tout ce qui va bien. Le système d’avertissement par mail est très bien fait et paramètrable. J’ai donné des accès à tous mes utilisateurs. Plex devrait s’inspirer de ce petit soft pour intégrer une fonctionnalité identique.
C’est bien connu: Bien mal acquis …blabla … Il m’est arrivé une mésaventure très récemment qui m’a bien ennuyée.
J’ai fait très récemment l’expérience de l’installation d’un thème vérolé sur mon blog. Dans ce qui suit, je vous expose mon erreur ainsi que les différentes mesures prises, non seulement pour les corriger mais également pour me prémunir d’un nouvel incident.
L’erreur conduisant au problème
Ainsi donc, je récupère sur un site de torrents bien connu le thème Divi. Un thème WordPress très puissant qui me semble pouvoir faire tout ce que je désire pour mon blog et plus encore. Divi est un thème payant (89$ par an). Le récupérer pour pas un rond est effectivement une aubaine semble-t-il. J’installe le thème par la procédure classique sur le blog que vous lisez en ce moment (upload du .zip), Divi apparaît bien dans la liste des thèmes. Je demande à prévisualiser avant d’activer le thème de façon à me rendre compte du rendu par défaut du thème « out of the box »… Et là, patatras … Page blanche, le site ne se charge plus … pas de message d’erreur, juste un blocage infini du chargement… Je flaire aussitôt une « arnaque », et je n’ai pas tort.
La seule solution que j’ai est de me connecter sur l’interface de mon hébergeur web, d’accéder par ftp à mon arborescence et de supprimer le répertoire du thème Divi. J’essaie également une restauration de ma base de données WordPress à l’aide des snapshots quotidiens réalisés automatiquement par l’hébergeur: Cela ne fonctionne pas, la restauration se bloque et met la base dans un statut foireux. Je constate que mon site est de nouveau accessible mais complètement vierge: Tout a disparu et l’installation de WordPress m’est proposée, Snif.
La résolution
En essayant de me connecter à ma base de données avec PhpMyAdminn je constate que l’accès m’est refusé: Le thème vérolé a modifié le mot de passe d’accès à la base. Heureusement, quelqu’un qui connait bien WordPress m’indique que ce mot de passe en clair est dans le fichier wp-config du site. je me connecte donc avec ce nouveau mot de passe à ma base de données vierge et j’essaie de modifier le, mot de passe afin d’éviter une nouvelle intrusion. Peine perdue, la base étant en « Invalid status: restoring », le changement de mot de passe n’est pas accepté.
Je décide donc quand même de faire repartir le blog (en créant quand même un ticket auprès de mon fournisseur pour remédier au problème de changement de mot de passe). J’exporte en local le snapshot de sauvegarde qui m’intéresse (drôlement confortable d’avoir une Save journalière), je supprime toutes les tables de ma base de données et je ré-importe: Tout fonctionne, je récupère tout mon site en quelques secondes.
Mesures prises
C’est la dernière fois que j’installe un truc piraté sur un blog de production…et même sûrement sur n’importe quoi d’ailleurs. En effet, ce n’est pas parce que je vais tester un truc vérolé pendant 15 jours avec un comportement exemplaire qu’il ne va pas déclencher un cataclysme au bout d’un temps défini. Si, par exemple, mon blog avait été effacé 35 jours après l’installation du thème vérolé, toutes les sauvegardes journalières auraient été corrompues (il y a un mois de Save quotidiennes) et j’aurais été bien plus embêté !
Création d’un Blog de test sur mon Synology de façon à tester avant de mettre en production. Je pourrais le faire en multisite chez mon hébergeur mais cela m’obligerait à partager ma base de données entre la production et le test. Je préfère deux bases séparées. De plus, sur mon Syno, c’est gratuit. je me demande même si je ne vais pas en faire une plateforme de secours avec recopie de la production tous les jours.
Installation du plugin WordFence permettant, dans sa version gratuite, le Scan de détection de malwares dans l’installation.
Installation d’un accès « authentification multifacteurs » (2FA) pour accéder à l’interface d’administration du blog (wp-admin) et également pour accéder à l’interface de mon compte chez l’hébergeur
Edit [08/10/2023] Exit Ubooquity, je suis passé sur Kavita
1. Introduction
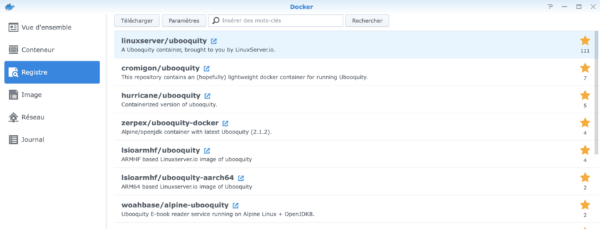
Pour cet article, je pars du principe que vous avez déjà installé Docker sur votre Synology. Si ce n’est pas le cas, je vous invite à lire cet article. Pour Docker en architecture Intel 64bits, il existe plusieurs conteneurs Ubooquity prêts à l’emploi. Ils n’ont pas tous la même popularité:
J’en ai testé deux et un seul des deux a démarré correctement:
linuxserver/ubooquity : Pas de problème
zerpex/ubooquity-docker : démarre, se plante au bout de 15 secondes puis redémarre et ainsi de suite …
En préalable, sur votre Synology, dans le répertoire /docker, créez un sous-répertoire linuxserver-ubooquity (avec votre compte administrateur).
2. Récupération de l’image
Dans Docker, sur votre Synology, allez sur Registre, tapez « ubooquity » dans le champ de recherche et sélectionnez le conteneur le plus populaire « linuxserver/ubooquity ». cliquez ensuite sur le bouton « Téléchargez ». Il vous est proposé de télécharger la « lastest » version, confirmez.
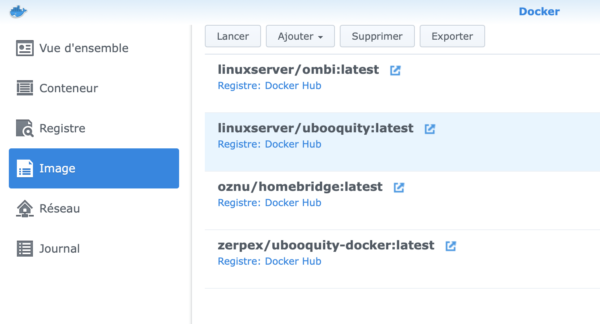
Positionnez-vous dans la partie « Image », sélectionnez « linuxserver/ubooquity » et cliquez sur « Lancer »:
3. Paramétrage du conteneur
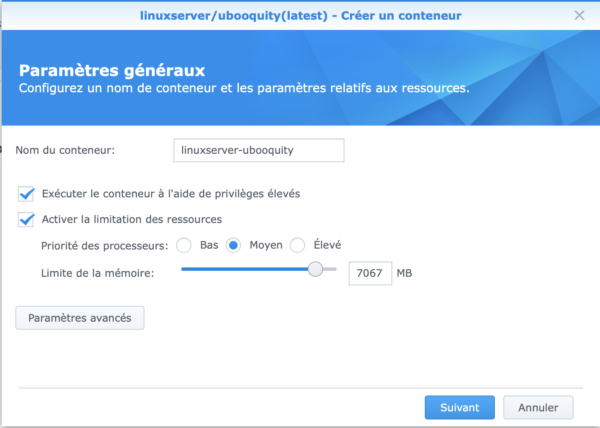
Vous arrivez alors au paramétrage du conteneur, vous pouvez vous inspirer de ce que j’ai mis (Attention , j’ai 8 Go de RAM sur le serveur donc j’ai forcé un peu la dose car on va le voir, Ubooquity peut être assez gourmand en RAM quand il indexe ses fichiers). Si vous n’avez que 2Go, ne dépassez pas 1536Mo (ou un truc comme ça).
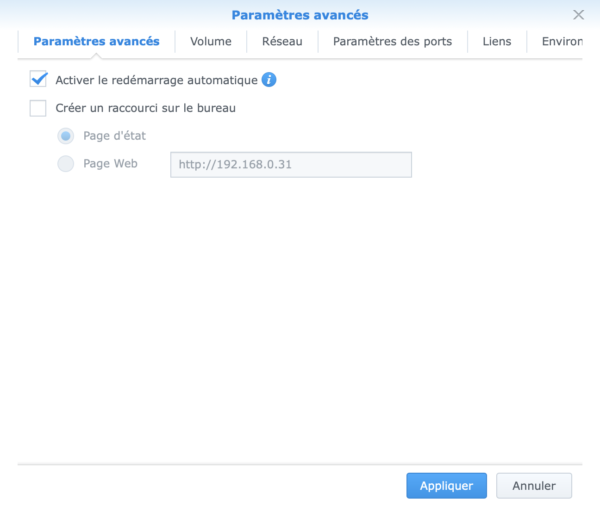
3.1 Paramétrages avancés
Cliquez ensuite sur « Paramètres avancés » et inspirez-vous …
3.2 Volumes
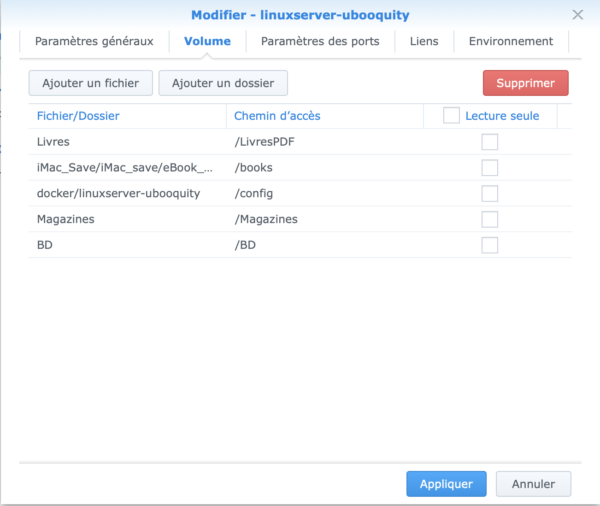
L’onglet « Volumes » est sûrement le plus « touchy » à saisir…
Quelques explications … Tout d’abord, le seul bouton que j’utilise est « Ajouter un dossier ». En effet, je veux indexer le contenu de dossiers/sous-dossiers dans lesquels j’ai mis mes fichiers (ePub, mobiles, pdf et quelques cbr/cbz). Attention aux majuscules/minuscules dans les noms …
A quoi sert ce paramétrage ? En fait, pour accéder à vos répertoires, le conteneur possède des points d’entrée. Ces points d’entrée sont dans la colonne « Chemin d’accès ». C’est à dire que le conteneur ne va connaître vos répertoires du Synology que par les noms que vous avez définis dans cette colonne. un seul point d’entrée et obligatoire et non modifiable : « /config ». tout le reste, vous pouvez mettre les noms de votre choix. En face de chaque « Chemin d’accès », vous avez le vrai répertoire dans le quel le conteneur va lire. On a donc par ce paramétrage mappé les points d’entrée du conteneur avec les vrais dossiers su Synology. Pour ma part, en voici la description (on peut créer autant de points d’entrée que l’on veut):
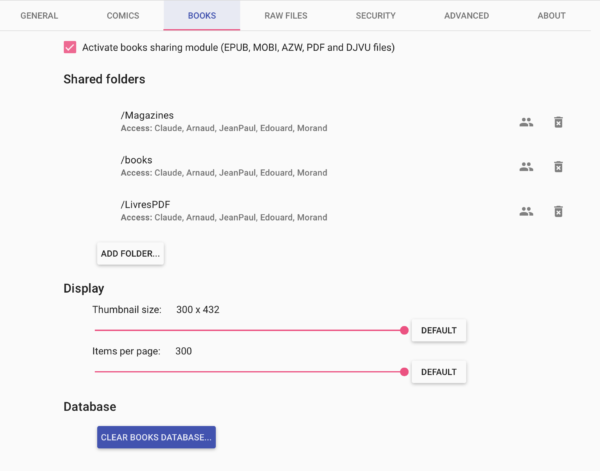
/LivresPDF : Contient tous les livres (hors BD) en PDF, répartis dans plusieurs sous répertoires. Le dossier Livres est à la racine de mon volume principal sur le Synology
/books : Contient tous les ePub/mobi de la bibliothèque Calibre. celle ci est sur mon Mac et je la recopie tous les jours dans un répertoire du Synology
/config : C’est l’endroit où Ubooquity va stocker ses infos, paramétrage, base de données, etc. C’est à vous de créer ce répertoire avant de démarrer le conteneur pour la première fois (indiqué au début de ce poste)
/Magazines : Tous les magazines en PDF (Le répertoire Magazines est à la racine du volume)
/BD : Toutes les BD (à la racine aussi …)
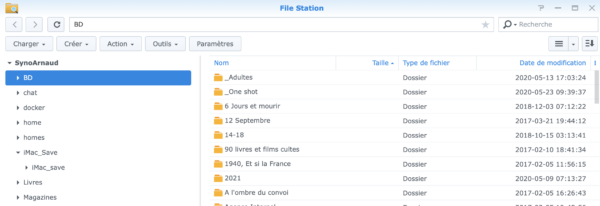
Pour vous donner une idée de l’arborescence sur le Synology:
Vous pouvez créer autant de points d’entrée que vous le souhaitez. C’est en effet lors de la configuration de Ubooquity une fois le conteneur lancé que nous définirons ces points d’entrée. Le seul obligatoire est « /config ».
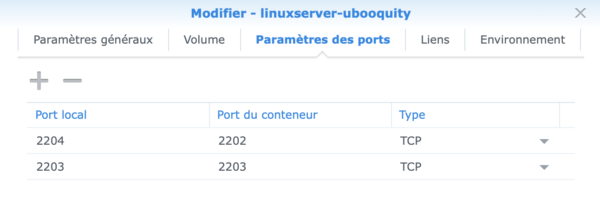
3.3 Paramètrage des ports de communication
Comme pour les répertoires, il faut mapper les ports « virtuels » du conteneur avec les vrais ports de communication du Synology. Dans cet exemple, les ports par défaut du conteneur sont 2202 et 2203. J’ai fait correspondre ces deux ports au 2204 et 2203 car le port 2202 du Synology était déjà occupé.
3.4 Les derniers onglets …
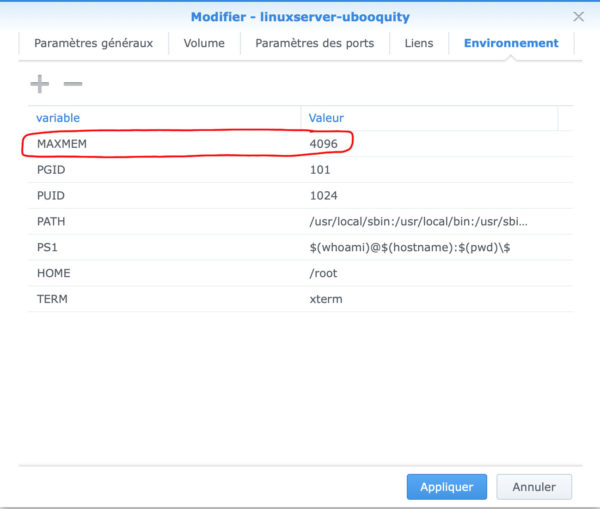
Dans l’onglet « Liens », je n’ai rien mis. Pour le dernier onglet, « Environnement’, si vous envisagez d’indexer des pdf de plus de 300Mo (c’est mon cas), je vous conseille de rajouter la variable MAXMEM que vous fixerez selon votre quantité de RAM et la quantité que vous avez indiquée dans le paramétrage du conteneur. La variable MAXMEM est passée en paramètre à Ubooquity lors du démarrage. Pour ma part, MAXMEM=4096. (Mo)
4. Lancement du conteneur
Un petit résumé de votre conteneur s’affiche à la fin de l’assistant, cochez la case « Exécutez ce conteneur lorsque l’assistant a terminé » puis validez le tout … Vous devriez avoir un écran similaire au mien:
5. Paramètrage de Ubooquity
Nous pouvons passer maintenant à la partie paramètrage de Ubooquity (pour l’instant, nous n’avons que paramétré le conteneur Docker pour son exécution).
5.1 Adresse IP du Synology
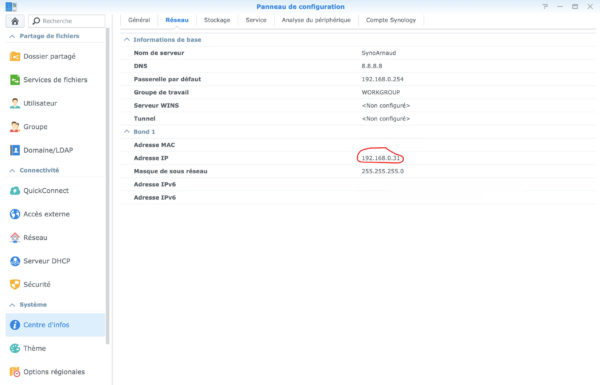
Allez sur votre navigateur web préféré, situé sur le même réseau local que votre Synology. vous devez connaître l’adresse IP de votre NAS. Si vous ne la connaissez pas, allez sur la console et lancez le panneau de configuration, vous la trouverez dans « Centre d’infos’. Il est conseillé pour la suite d’avoir attribué une adresse fixe au serveur Synology, c’est bien plus simple …(Remarque, on peut aussi accéder au serveur via son nom, ici : SynoArnaud.)
5.2 Administration de Ubooquity
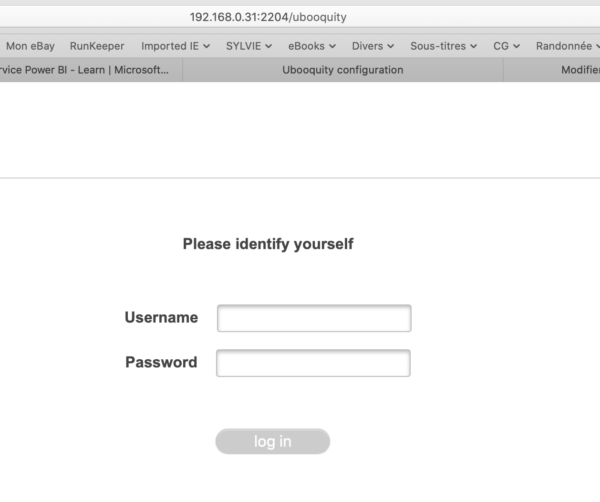
Retour donc dans votre navigateur, nous allons nous connecter à l’écran d’administration de Ubooquity. Le port d’admin de Ubooquity pour ce conteneur est 2203, port que nous avons mappé sur le Synology en 2203 (pas de changement). L’adresse IP de mon Synology étant 192.168.0.31, je tape la ligne suivante dans la barre d’URL du navigateur:
Pour le premier lancement, il vous sera demandé de définir un mot de passe administrateur, vous pourrez ensuite vous connecter en saisissant ce mot de passe pour arriver à l’interface de configuration:
Je ne vais pas définir ici toutes les options disponibles dans Ubooquity. Je vais détailler uniquement le paramétrage des points d’entrée (définis lors de la création du conteneur Docker) ainsi que la création d’un utilisateur.
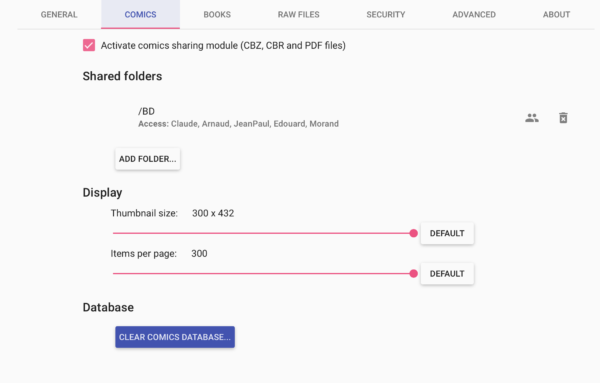
5.2.1 Les bandes dessinées
Nous nous rendons d’abord dans l’onglet « Comics » afin de paramétrer l’entrée (ou les entrées) des bandes dessinées:
On peut voir que j’ai créé un point d’entrée /BD correspondant au /BD de la colonne « Chemin d’accès » qui va pointer sur le répertoire /BD. Ceci est un peu perturbant car tout a le même nom… Un peu plus loin, pour les livres, c’est différent, vous comprendrez peut-être mieux. C’est en cliquant sur le bouton « ADD FOLDER » que Ubooquity vous proposera la liste des points d’entrée connus par lui-même et que vous avez définis lors du paramétrage du conteneur. Lorsque vous aurez créé des utilisateurs, vous pourrez les ajouter à l’aire de la petite icône à droite de la ligne afin qu’ils puissent accéder à la ressource.
5.2.2 Livres autres que les BD
On voit les 3 points d’entrée qui ont été définis précédemment lors de la création du conteneur. Si vous décidez d’ajoutez un nouveau répertoire à scanner par Ubooquity, vous avez deux solutions:
C’est un sous-répertoire de ce qui existe dèjà et qui est défini dans Ubooquity: Vous n’avez rien à faire, Ubooquity va le scanner au prochain scan.
C’est un nouveau répertoire hors de tout ce qui existe dans Ubooquity: Vous devez arrêter le conteneur, modifier le paramétrage et rajouter un dossier dans l’onglet Volumes du conteneur, relancer le conteneur (vous ne perdrez rien, pas d’inquiétude). vous devez ensuite rajouter le point d’entrée dans le paramètrage (comics ou books) et relancer un scan …
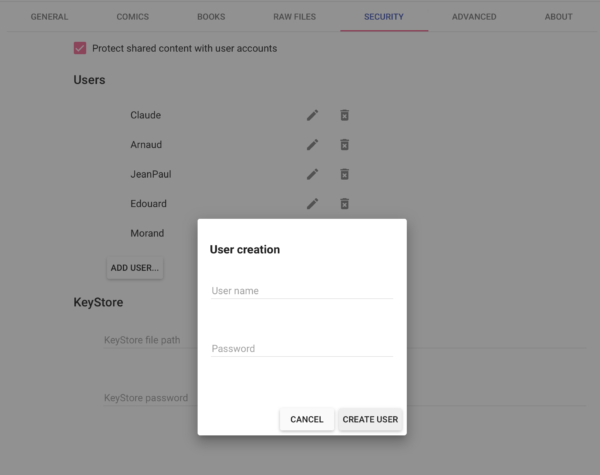
5.2.3 Création d’un utilisateur
Pour la création d’un utilisateur, cela se déroule dans la partie « Security »:
Faire « ADD USER », donner un nom et un mot de passe pour le nouvel utilisateur et cliquer sur « CREATE USER ». rien de plus simple.
5.3 Le premier scan…
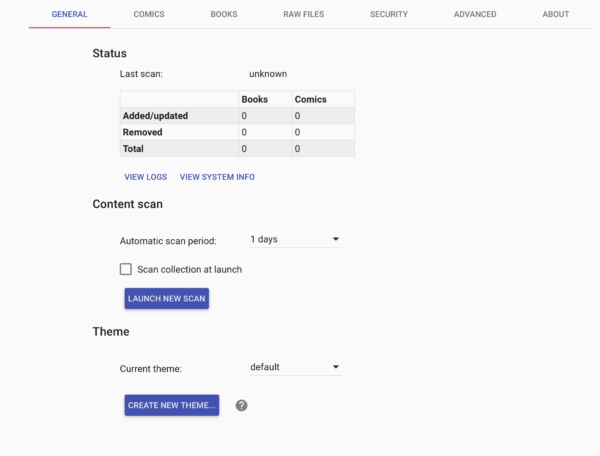
Vous pouvez revenir à l’onglet « GENERAL » et cliquer sur « LAUNCH NEW SCAN ».
A signaler: Le premier scan est long (48h dans mon cas pour presque 40000 documents …) car l’intégralité des répertoires est parcourue et indexée. Par la suite, seuls les nouveaux fichiers/répertoires seront indexés (Ubooquity détecte les changements de nom, de date et de taille).
L’utilisation de Ubooquity.
Jusque là, nous n’avons pas encore utilisé le logiciel, nous l’avons installé, paramètres et peuplé. Pour accéder à l’interface utilisateur, il faut se connecter sur l’autre port de communication défini en 3.3. Le port d’utilisation à utiliser est le 2204 (mappé sur le 2202 du conteneur). Il faut avoir de préférence défini des utilisateurs avant d’accéder à l’interface de consultation.
Comme pour l’interface d’administration, rendez-vous dans votre navigateur. dans mon cas, il me suffit de taper l’adresse du Synology suivie du port 2204/ubooquity pour accéder au logiciel:
Il suffit d’entrer le nom et mot de passe d’un utilisateur créé en 5.2.3 pour accéder au paradis … Tous vos documents apparaissent dans les différentes sections correspondant aux répertoires de votre Synology.
6. Accès au serveur depuis l’extérieur de votre réseau local (c’est à dire depuis le monde entier).
Ce qui suit permettra décrit le paramètrage à mettre en oeuvre afin d’accéder à Ubooquity en dehors de chez vous et de permettre ainsi à vos amis de bénéficier des services de votre serveur Ubooquity. Je suis pour ma part chez Free, l’exemple ci-dessous concernera donc un paramétrage sur la box de Free.
6.1 Un Synology en IP fixe (statique) sur votre réseau local.
Il est important que votre serveur Synology ait tout le temps la même adresse IP sur votre réseau local. je vous invite pour cela à lire cet article.
6.2 Redirection des ports sur la Box de Free.
Nous avons besoin d’accéder aux ports 2203 et 2204 du Synology (définis au point 3.3). Il faut accéder à l’interface de paramétrage de la Freebox à l’adresse : http://mafreebox.freebox.fr
En bas à gauche, le bouton rouge vous permet de vous connecter en mode admin et à sortir du mode « Invité ». On arrive à l’écran suivant:
Cliquer sur « Paramètres de la Freebox:
Sélectionner l’onglet « Mode avancé ». puis l’icône « gestion des ports »:
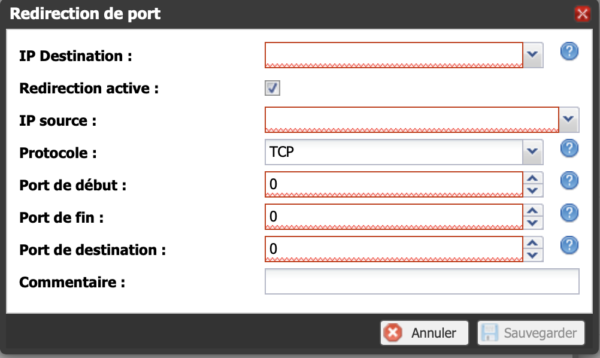
Une liste s’ouvre (plus ou moins remplie, peut être même vide …). Cliquer sur « Ajouter une redirection », le formulaire de saisie d’une redirection apparait:
Il nous faut rediriger les deux ports donc nous ajouterons 2 redirections (donc deux fois ce formulaire). pour la première redirection, saisissez les informations suivantes:
IP Destination: Choisissez votre NAS dans la liste déroulante (ici: SynoArnaud)
IP Source: En général, pas de choix possible, c’est « Toutes »
Protocole: Laisser TCP
Port de début: 32xxx (c’est à vous de choisir une valeur de port pour se connecter de l’extérieur. il est possible que 32xxx soit indisponible car déjà utilisée, dans ce cas en choisir une autre, proche). Je ne vous mets pas ma vraie valeur par sécurité. une valeur correcte serait 32745 par exemple
Port de fin: Même valeur que port de début
Port de destination: 2203
Vous devez avoir 2 redirections dans votre liste à la fin du paramétrage. L’accès à l’interface admin de Ubooquity se fait par le port 32xxx et l’accès pour consultation par le port 32yyy.
Vous avez donc une adresse internet pour votre serveur Synology. cette adresse est du style : http://xxxxxxxxxxx.myds.me:32xxx
L’autre solution serait de passer par votre adresse IP fixe (à demander à votre opérateur internet s’il en propose. c’est mon cas chez Free où je possède une IP fixe avec ports non partagés).
Pour accéder de l’extérieur à votre serveur Ubooquity:
en mode admin: http://xxxxxxxxxxx.myds.me:32xxx/ubooquity/admin
en mode consultation : http://xxxxxxxxxxx.myds.me:32yyy/ubooquity
J’ai découvert il y a un an et demi cette perle qu’est le logiciel Ubooquity ! Je l’utilise sur mon Synology mais Ubooquity peut être utilisé sur n’importe quoi: un PC, un Mac, un RaspBerry. Il existe même des containers Docker tout faits et qui fonctionnent très bien ! Mais d’abord, Ubooquity, c’est quoi ?
Imaginez un Plex pour les livres et PDF et vous aurez une petite idée de ce que peut être Ubooquity. Ubooquity présente dans une belle interface web l’ensemble de votre bibliothèque, qu’il s’agisse de PDF, CBR,epub,mobi, etc…
Le site officiel de Ubooquity est ici. Le logiciel est gratuit. J’ai indexé avec Ubooquity mes 10716 bandes dessinées (réparties dans des répertoires, un répertoire par collection) et mes 17806 epub, mobi et PDF. La différence entre Plex et Ubooquity, c’est que Ubooquity ne gère pas de métadata et ne va pas retrouver les informations concernant chaque BD, epub ou PDF. Ubooquity se « contente » de les présenter, d’offrir un accès aux utilisateurs que vous créez, d’offrir la consultation et/ou le téléchargement en local ou à distance des documents.
Les écrans
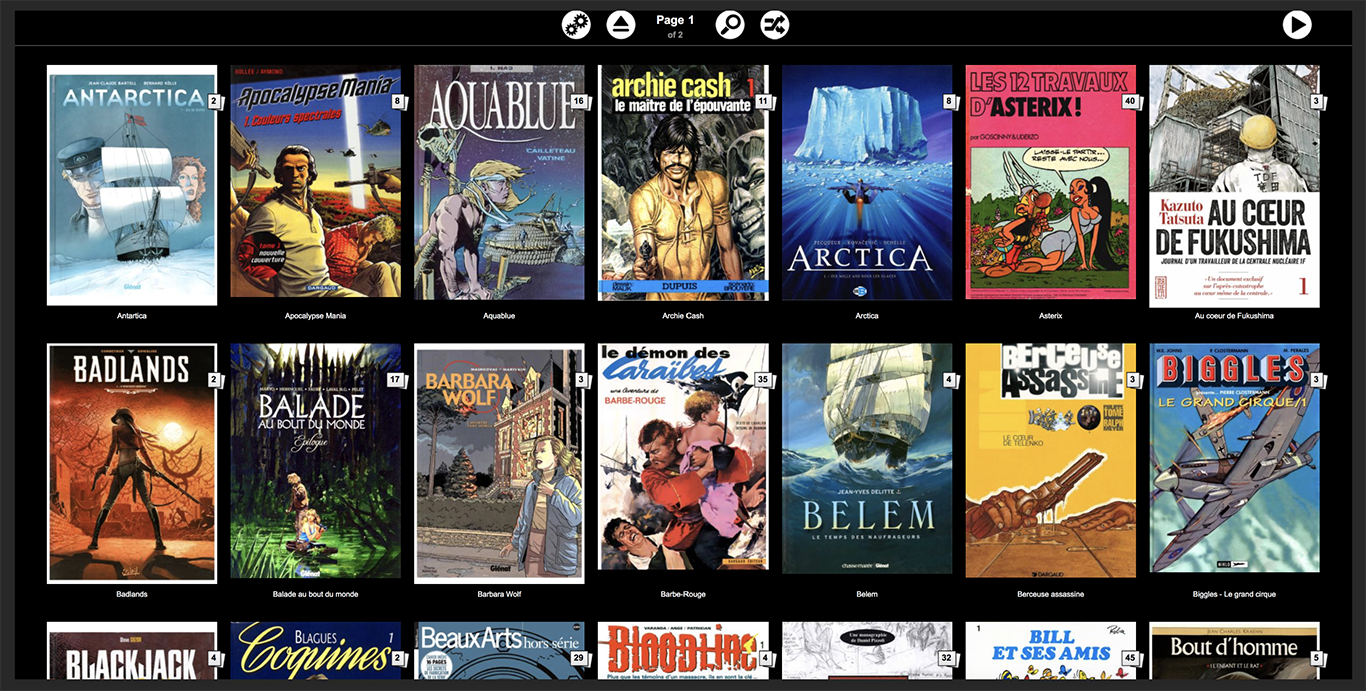
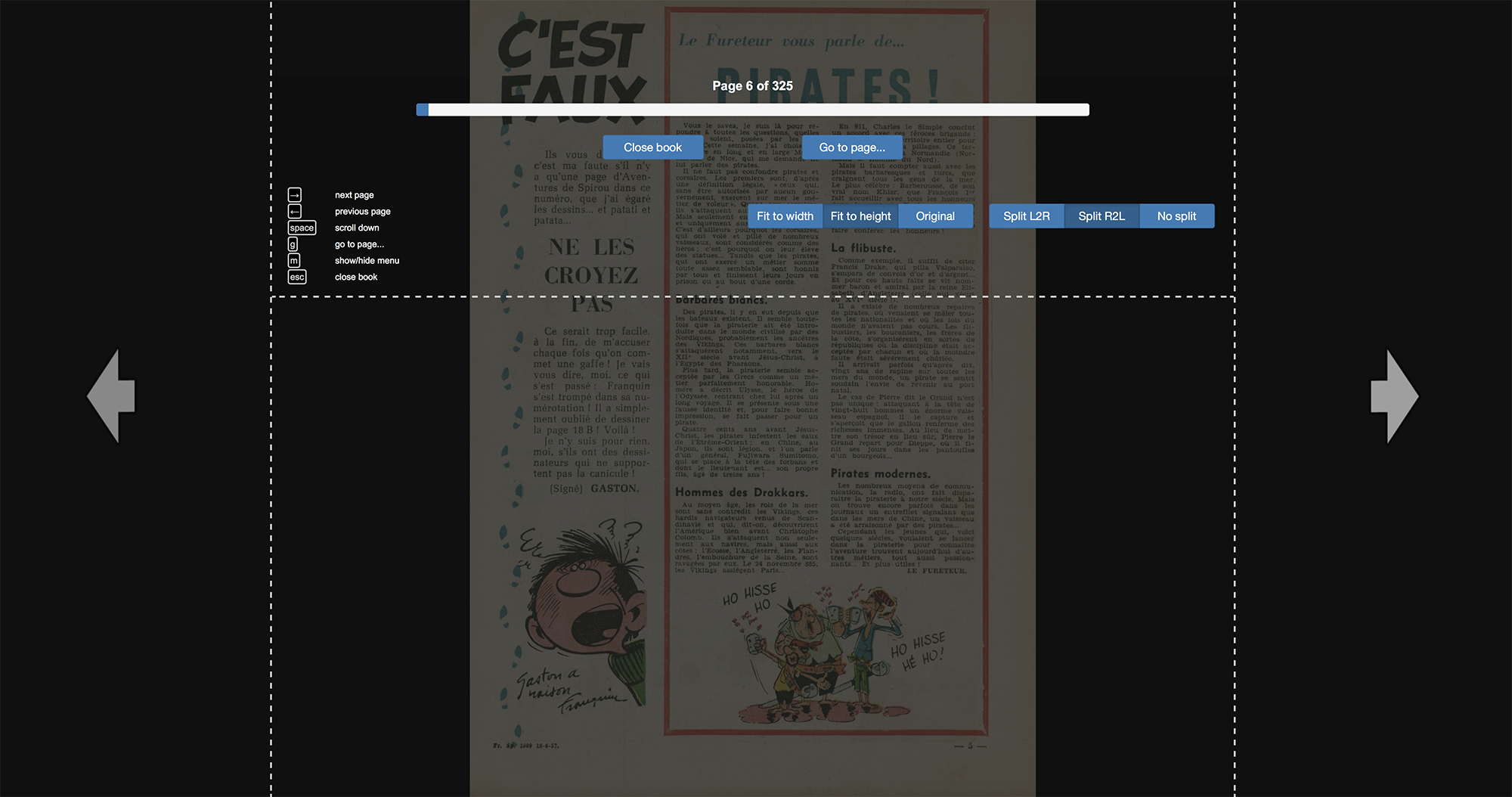
Voici un exemple de page Ubooquity pour les BD. Chaque Couverture représente une collection. En haut à droite de la couverture s’affiche le nombre de BD dans la collection. La partie supérieure de l’écran permet de naviguer entre les pages ou de rechercher dans les titres. Les BD peuvent être au format PDF ou CBZ/CBZ.
Pour les magazines, l’affichage est identique:
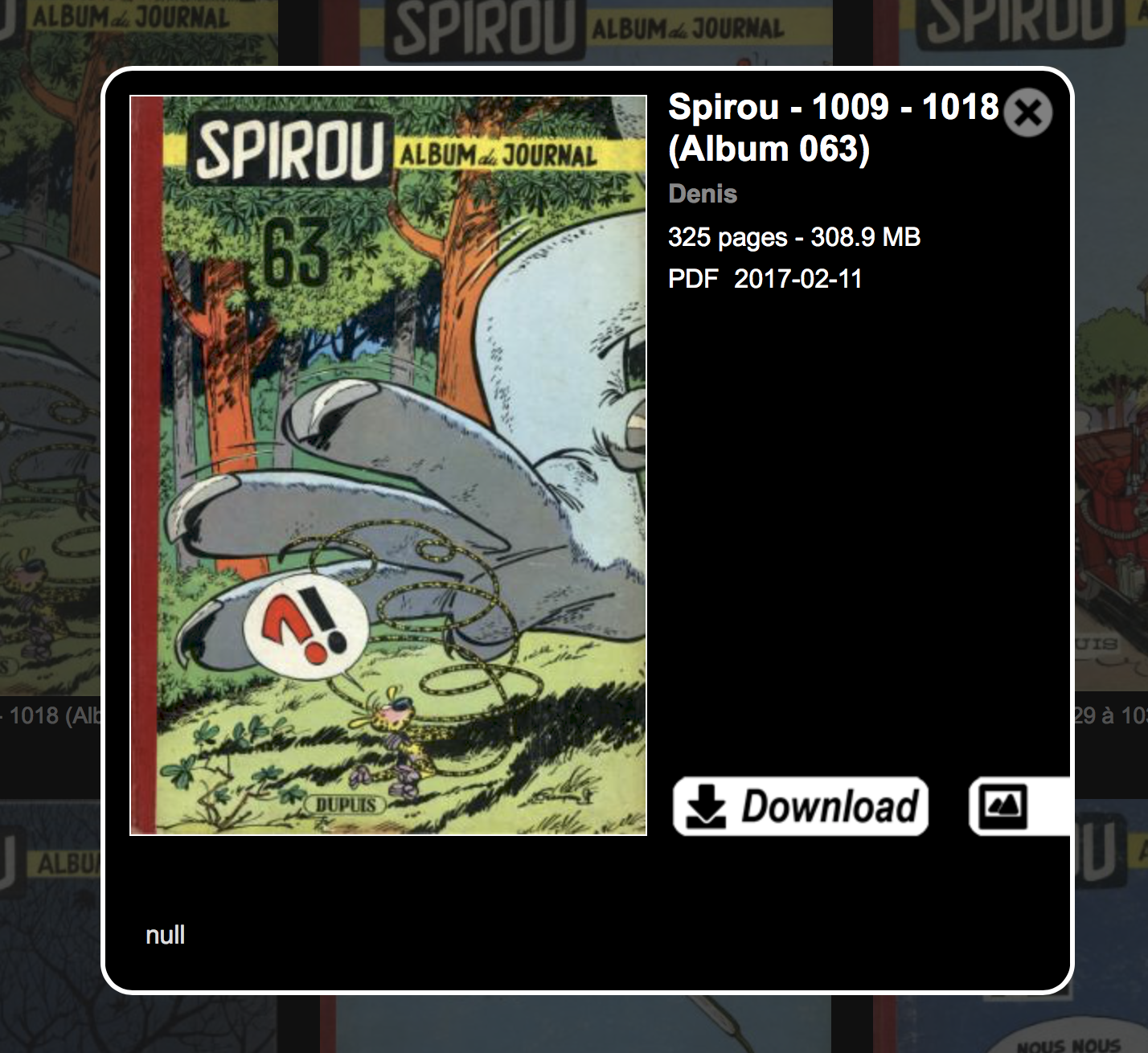
Lors de la sélection d’un document, le choix proposé est soit la lecture en ligne (par un lecteur web très bien fait) ou bien le téléchargement:
Le petit picto en bas à droite de la fenêtre mêne à un lecteur web avec pas mal d’options pour la lecture online:
Vous pouvez demander à Ubooquity de scruter votre librairie Calibre si vous en avez une. Ubooquity ne va pas attaquer la base de données Calibre mais va parcourir l’arborescence et intégrer les fichiers de métadonnées créés par calibre de façon à, pourvoir présenter des informations intéressantes avant le download ou la lecture online (pas de lecture online avec les mobi. c’est possible uniquement avec les epub. Il est même possible d’accéder à votre serveur Ubooquity à partir de votre liseuse pour y télécharger directement le fichier epub (kobo) ou mobi (Kindle).
L’administration
L’interface administrateur n’est certes pas la plus sexy du moment. vous pouvez créer autant d’utilisateurs que vous le souhaitez et leur attribuer des droits sur les différentes sections de votre bibliothèque. Si vous laissez tourner la machine sur laquelle vous avez Ubooquity 24h/24h, votre bibliothèque sera accessible pour tous vos amis, quelque soit l’endroit où ils se trouvent dans le monde (à condition d’ouvrir les ports qui vont bien sur votre box) et tout moment.
Ubooquity possède 3 sections qui sont: Comics, Books et Rawfile.
La section Comics permet d’indexer des pdf et des CBR/CBZ. La section Books permet d’indexer des PDF , des epub et mobi et la section rawfile … Je ne sais pas trop ! (je n’ai pas de formats exotiques !)
Conclusion
Voilà pour la présentation de cette petite perle qu’est Ubooquity. Je n’ai pas installé la dernière version disponible car la version installée depuis 18 mois sur mon Synology tourne très bien. L’indexation a lieu chaque jour. Il m’a quand même fallu 8Go de RAM sur le Syno pour faire tourner le container Docker (il y a quelques fuites mémoires lors de l’indexation et celle-ci fond très vite). mais c’était seulement pour la première itération… par la suite l’indexation se fait par différence avec la précédente, en incrémental.
Ubooquity est un magnifique logiciel, trop peu connu, assez facile à mettre en oeuvre et offrant des services incomparables semblables à Plex dans le domaine du document numérique.
SI vous utilisez aussi Ubooquity, n’hésitez pas à déposer un commentaire. Si vous vous posez des questions, n’hésitez pas non plus !
A la demande générale, vous pourrez trouver un tuto pour l’installation et le paramètre de la solution ici
J’ai peaufiné un système de sauvegarde qui me permet d’être à peu près à l’abri de tout incident…
Mon cahier des charges est le suivant :
Sauvegarde des données personnelles de ma machine principale (un Mac).-
Sauvegarde de certains répertoires du Synology.
Récupération des données « en bloc » en cas d’incident sur une machine locale (iMac ou Synology).
Récupération facile d’un fichier en particulier.
Récupération des données en cas de destruction totale des équipements.
Automatisation du procédé de sauvegarde.
J’ai mis en place plusieurs mécanismes pour répondre à cette problématique :
Tout d’abord, le Mac est sauvegardé localement sur un disque externe relié au Synology via Time machine. Cette sauvegarde est réalisée toutes les 5 minutes. Pour avoir déjà restauré entièrement un Mac à l’aide de Time Machine, j’ai une entière confiance en ce système. C’est mon premier niveau de sauvegarde et de restauration, celui que j’utilise quand j’ai effacé un fichier par erreur ou un peu trop vite…
Mes fichiers personnels présents sur le Mac sont en plus répliqués sur le NAS Synology une fois par jour. Le répertoire du Mac Utilisateurs/ArnaudL (en gros la petite icône « maison » du Mac est ainsi copiée de façon incrémentale dans un répertoire spécial du Synology. J’ai testé plusieurs outils pour cette Synchro et j’ai eu beaucoup de mal à trouver un outil simple et parfait. L’utilitaire Sync Folders Pro (payant) ne me copiait pas tout et ignorait purement simplement des répertoires. L’outil Synology Cloud Station Drive (client associé à Cloud Station Server sur le Syno) n’était pas non plus parfait et m’ignorait des datas. Je n’ai pas testé la solution Bittorrent Sync ni la solution Crashplan. J’ai finalement trouvé la perle rare: Un outil simple, fiable et gratuit: FreeFileSync !
La période Amazon Drive illimité …
Pour sauvegarder les éléments précieux du Syno, j’ai pris un abonnement à Amazon Drive qui pout 70€ par an permet de stocker un volume illimité de données sur un serveur « dans le cloud ». Je n’ai pas de problème de sécurité à prendre en compte, j’imagine qu’Amazon a bien mieux à faire que de fouiller dans mes fichiers. Cette offre d’Amazon a malheureusement pris fin et mon abonnement sera terminé en mars 2018. Amazon me propose maintenant de sauvegarder mes données pour environ 800€ par an (il faut dire que je sauvegardais une bonne partie du NAS en plus de mes données brutes personnelles…).
Le AirBnb de la sauvegarde !
Comme il n’était plus possible de sauvegarder mon NAS sur Amazon avec l’excellent logiciel de sauvegarde HyperBackup fourni par Synology, j’ai dû me tourner vers une autre solution…
Hyperbackup permet de sauvegarder vers un autre NAS Synology. Mon plus proche collègue (et aussi ami) possède un Synology et comme moi, il est fibré. Nous avons donc installé une sauvegarde symétrique de nos Synology. J’ai fourni un disque externe qu’il a branché sur son Synology et j’ai fait de même avec le disque externe qu’il m’a fourni. Et toute les nuits, les données essentielles de mon Synology (dont la copie de mon répertoire utilisateur sur l’iMac) sont sauvegardées. C’est une sauvegarde incrémentale et cryptée (c’est à dire que moi seul peut voir le contenu de cette sauvegarde). La première itération est un peu longue (800 Go à passer par la fibre, à raison de 30Go par heure environ) mais après, quelques minutes chaque nuit sont suffisantes pour sauvegarder les changements. Ainsi, même en cas de vol ou destruction du matériel, j’ai une copie de mes données quelque part en dehors de chez moi. De plus, J’ai demandé à Hyper Backup de garder 99 versions d’historique de fichiers. Je peux donc remonter dans le temps et récupérer des vieux fichiers si j’en ai besoin. Cette précaution est particulièrement utile en cas d’attaque par un ransomware.
J’espère que cet article vous aura servi. N’oubliez pas que la sauvegarde de vos données est une chose primordiale, que les données numériques sont des petits objets très fragiles qui peuvent disparaitre par milliards en une fraction de seconde…
Sur la photo, on peut voir le Synology DS416+ (dans son débarras car l’objet est assez bruyant, à gauche un premier disque externe abritant les torrents en partage, au dessus un premier disque externe pour la sauvegarde TimeMachine et encore au dessus et connecté en façade, le disque externe contenant la sauvegarde de mon ami).